INFORMATION FLOW DURING EPIDEMICS


In this blog post I will be talking about Epidemic Information Dissemination in Distributed Systems.
Epidemic algorithms in general are robust ,easy to deploy and highly resilent to failures.These are effective for information propagation in large peer-to-peer (P2P) systems on Internet.It is possible to adjust the parameters of an epidemic algorithm to achieve high reliability despite process crashes and disconnections, packet losses, and a dynamic network topology.The peer-to-peer (P2P) computing model offers an appealing alternative to conventional server-client model for large scale applications in distributed settings.The P2P approach gets rid of central points of failure and associated performance bottlenecks.It balances the problems—such as forwarding messages or storing data—among all system processes, each of which requires only local knowledge of the system state.
Epidemic algorithms mimic the spread of a contagious disease.Just as infected individuals pass on a virus to those with whom they come into contact, each process in a distributed system relays new information it has received to randomly chosen peers rather than to a server or cluster of servers in charge of forwarding it. In turn, each of these processes forwards the information to other randomly selected processes, and so on.
Every process that receives a message to be disseminated forwards it by default to a randomly chosen subset of other processes. Each of these infected processes in turn forwards the information to another random subset.
Once it has started, an epidemic is hard to eradicate: It only takes a few people to spread a disease, directly or indirectly, to the community at large. An epidemic is also highly resilient—even if many infected people die before they transmit the contagion or are immunized, the epidemic will reliably propagate throughout the population.
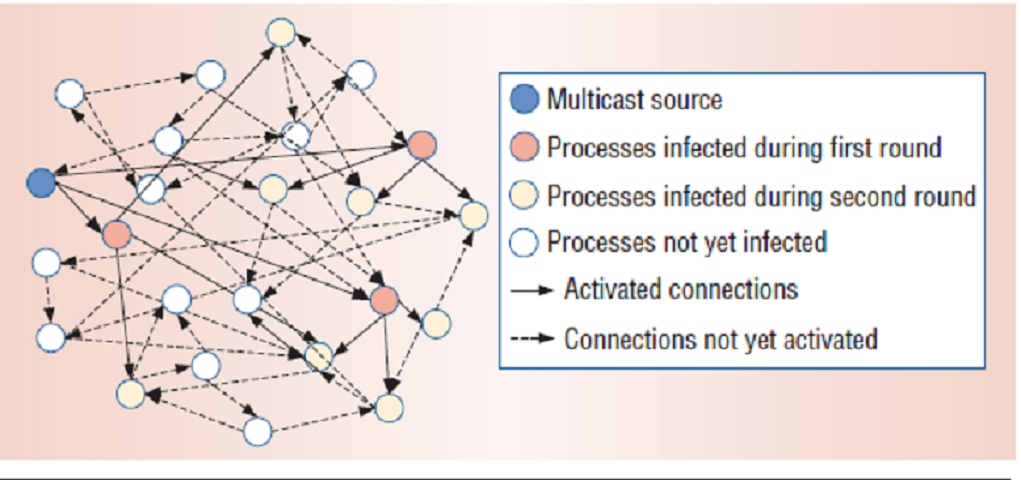
Figure of A multicast source, represented by the blue circle, sends a message to be disseminated in a system.
Epidemic algorithms exhibit bimodal behavior.
They either achieve successful delivery to almost all processes or only reach a negligible portion of the processes.
Implementing an epidemic algorithm in a practical setting requires addressing specific design constraints that the system processes resource requirements impose with respect to-:
• Membership—how processes get to know each other, and how many they need to know;
• Network awareness—how to make the connections among processes reflect the actual network topology to ensure acceptable performance;
• Buffer management—which information to drop at a process when its storage buffer is full;
•Message filtering—how to take into account the actual interest of processes and decrease the probability that they receive and store information of no interest to them.
Now a brief information on all these -
1.MEMBERSHIP
In Information dissemination, every process p that receives a message can forward it only to other processes that it knows. How a given process p acquires its own specific membership information impacts the performance of subsequent disseminations and is thus central to the design of scalable implementations of epidemic algorithms.One possible solution is to integrate membership with the epidemic dissemination itself: When a process forwards a message, it includes in this message a set of processes it knows; thus, the process that receives the message can update its list of known processes by adding new ones.
Any criteria we choose should fulfill following properties :
1.Uniformity. Every process in an epidemic algorithm forwards every message it receives to a subset of processes chosen uniformly at random among all processes in the system
2.Adaptivity. If the partial view size and the dissemination parameters are predetermined and do not evolve as the system grows the probabilistic guarantees of delivery will vary with system size.
3.Bootstrapping. A closely related question is how processes initially get to know one another. This requires some external mechanism to initiate and trigger the dynamic membership scheme.
2.NETWORK AWARENESS
Epidemic algorithm ensures that messages are mostly forwarded to processes within the same branch of the hierarchy, thereby limiting the load on core network routers. Only a few connections between sub- hierarchies are required to ensure successful implementation of epidemic dissemination.
One possibility is to incorporate some form of administration service that is aware of the actual hierarchy.
Another approach is to set up a two-level hierarchy in which processes favor the choice of low connectivity neighbors as infection targets.
Another solution relies on a tree-like organization of processes that induces a hierarchy and provides each process with a membership that grows logarithmically with system size.
3. BUFFER MANAGEMENT
Every process that receives a message must buffer it up to a certain capacity and forward it a limited number of times,each time to a randomly selected set of processes of limited size.Depending on the broadcast rate,a process’s buffer capacity might be insufficient for it to forward every message it receives enough times to achieve acceptable reliability.
Directing a process to drop new messages when its buffer is full would prevent forwarding such messages.On the other hand,instructing a process to drop old messages when its buffer is full and new messages come in could result in some old messages not being forwarded a sufficient number of times.

The process of determining the bufferers of a data message is initiated by the source.When the bufferers are
determined their ids are piggybacked to the data message and sent to the bufferers firstly.Then there is a tradeoff in the decision for the STL value of major aim is to distribute the buffering load to the entire bufferer request messages.If the STL value is chosen system evenly.As bufferers are distributed evenly among large enough,uniform selection of bufferers would be the peers,the load of cooperative data dissemination easily achieved since the request message will be able to would also be well distributed among the peers.
4. MESSAGE FILTERING
Ensuring that every message reaches every process in the system is the design objective when all processes are equally interested in receiving all messages. However, different groups of processes can have distinct interests. In this scenario, it might be desirable for the algorithm to first partition processes in the groups and then follow this objective for disseminating messages within each group.An alternative approach is to enable processes within a single system to express specific interests and make sure they receive the appropriate messages more precisely, to increase the probability P1 that a process receives a message it is interested in and simultaneously decrease the probability P2 that a process receives a message in which it is not interested.
Conclusion
Implementing epidemic dissemination in a largescale system requires connecting and managing the peers in a fully decentralized manner, thereby creating a peer-to-peer overlay network. Beyond the specific challenges we have discussed, a wider research agenda consists in extending the scope of epidemic algorithms from information dissemination to other applications that leverage the overlay network. Such applications would, for example, include content search, content-based publish/subscribe,and file sharing.
References-:
1.Epidemic Information Dissemination in Distributed Systems by Patrick T. Eugster ,Rachid Guerraoui,Anne-Marie Kermarrec, Laurent Massoulié.
2.Stepwise Probabilistic Buffering for Epidemic Information Dissemination by Emrah Ahi, Mine C;aglar and Oznur Ozkasap.
3.Information Dissemination using Epidemic Routing with Delayed Feedback by Yezekael Hayel and Hamidou Tembine
4.Sampling Strategies for Epidemic-Style Information Dissemination by Milan Vojnovic´, Varun Gupta, Thomas Karagiannis, and Christos Gkantsidi.
No comments:
Post a Comment